
Der Begriff Big Data ist in der IT eines der aktuell meist diskutierten Hype Schlagwörter wenn es zum Thema Industrie 4.0 geht. Anhand großer Datenmengen und ausgeklügelter Algorithmen sollen Strukturen und Tendenzen im Datenchaos ermittelt werden. Was im großen Stil durch IoT (Internet of Things) mit Cloud Servern usw. schon in manchen Bereichen Realität wird, kann aber auch im kleinen Umfang für erhebliche Mehrwerte sorgen.
Testlabor Szenario
In diesem Beispiel will ich aufzeigen, wie man aus mehreren Datenquellen und dem Splunk dies einfach in wenigen Schritten realisieren lässt. Da ich mehrere Linux Systeme im heimischen Labor laufen lasse, kommen für jeden Host separate Log Files zustande. Die Kunst ist nun, nach dem Prinzip „Big Data„, diese passend zu konsolidieren.

Schema vom Testaufbau mit Splunk
Hierbei versenden die lokalen Hosts ihre gernerierten Logs durch Anpassung des Log Daemons per UDP (User Datagram Protocol) alle ihre Informationen an einen zentralen Syslog Server.
Stärken von Splunk
Splunk ist für das Sammeln und Auswerten von großen Datenmengen mittels System Logs, oder durch OPC (Open Platform Communications) gesammelte Maschinendaten sowie andere standardisierte Quellen prädestiniert. Im Gegensatz zu den herkömmlichen Datenbanken wie MySQL, Oracle, DB2 usw. mit ihren Tabellen bzw. Schemas gibt es bei Splunk keine vorgegebene Struktur. Diese wird dynamisch bei der Indexierung der Datenströme generiert. Jeder Eintrag bekommt einen Zeitstempel und wird durch vorhandene bzw. manuell erstellte Mustererkennungen indexiert und abgespeichert. Bei der Abspeicherung werden keine Daten konsolidiert, was somit eine 100% reproduzierbaren Logauswertung in die Vergangenheit ermöglicht.
Bei der Suche wird eine Feldextraktion der Splunk Daten durchgeführt. Zur besseren Auflistung werden die Ergebnisse durch mehrere Felder indexiert.
Screenshot Splunk Index Sources
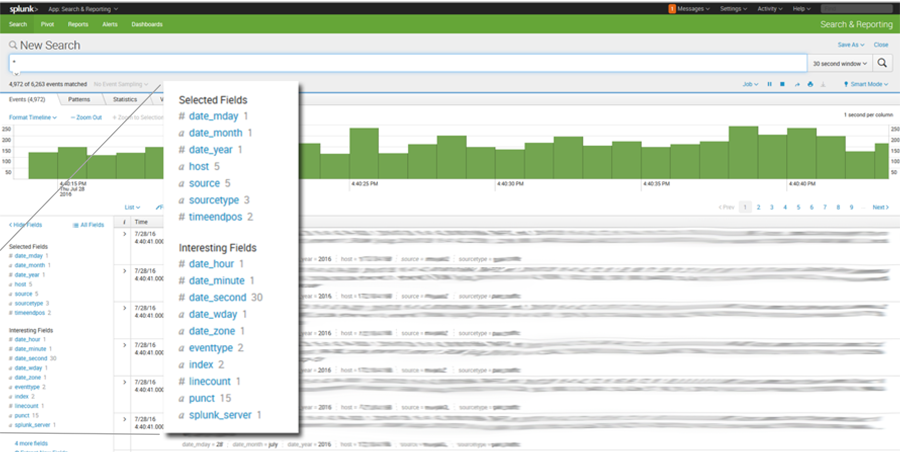
Screenshot Splunk Suchmaske
Ressource für Splunk
Splunk an sich ist ein sehr Ressourcenhungriges System. Einige Eckdaten für die Systemvorraussetzung:
- RAM: 12 GB
- CPU Kerne: 2x 6 CPU Kerne
- CPU Power: 2+ GHz
Anpassung der Log Dateien auf dem zentralen Linux Server
Splunk kann direkt als Syslog Server fungieren und die UDP Pakete der versendenden Hosts entgegen nehmen. In meinem Aufbau weiche ich aber von der allgemeinen Funktion ein wenig ab. Stattdessen wird zum Empfangen und abspeichern der Syslogs, den für Linux vorhanden Daemon RSyslog verwendet. Dadurch bin ich für spätere weitere Verarbeitungen mittels Dritthersteller Tools flexibler. Als Beispiel könnten später die gespeicherten Log Files ein SIEM (Security Information and Event Management) System befüllen, ohne das Einstellungen vom Syslog an jedem Host nachträglich angepasst zu werden.
Zur besseren Administration und Separierung unterteile ich jeden Host in ein eigenes Logfile. Hierbei muss die Konfigurationsdatei des Rsyslog mit den folgenden entsprechenden Zeilen erweitert werden.
$template DynaFile,"/var/log/hosts/%HOSTNAME%" *.* -?DynaFile
Anpassung am Splunk
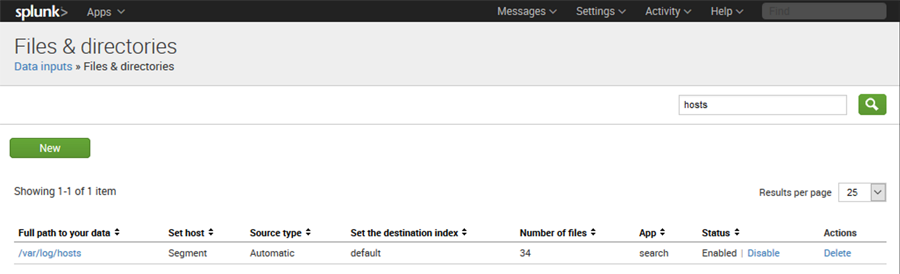
Damit die Syslogs dennoch verarbeitet werden, wird als Index Source das /var/log/hosts Verzeichnis als Quelle angegeben.
Screenshot Splunk Index Sources
Diese Methode ist besser als jede einzelne Datei selbst als Quelle anzugeben, da allein durch die Anpassung eines zusätzlichen neuen Hosts automatisch dieser dann durch Splunk indexiert wird.

Screenshot Splunk Datennutzung nach Quellen
Lizenzen
In dem gezeigten Beispiel wird die openFree Lizenz verwendet. Die besagt, dass nicht mehr als 500 MB an Daten pro Tag verarbeitet werden kann. Zudem sind nur eine begrenzte Anzahl an simultanen Abfragen auf dem Splunk Server möglich. Bei Verstößen dieser Limits deaktivert Splunk einige seine Search Funktionalitäten. Splunk sammelt weiterhin die Daten, aber man kommt nicht mehr an diese heran. Nicht zu gravierende Vergehen werden in einer Art „Bewährungsstrafe“ die deaktivierten Funktionen nach einer gewissen Zeit wieder frei geschaltet. Gröbere Mißachtung der Limitgrenze führt zu einem kompletten abschalten der Funktionen. Dann hilft nur noch eine Neuinstallation der Splunk Instanz.
One Comment
Windows Eventlog Analyse mittels Splunk – My IT Blog
[…] dem letzten Beitrag zur zentralen Syslog Analyse durch Splunk, möchte ich nun eine weitere Möglichkeit zur zentralen Loganalyse aufzeigen. Diesmal steht eine […]